{kind=link}
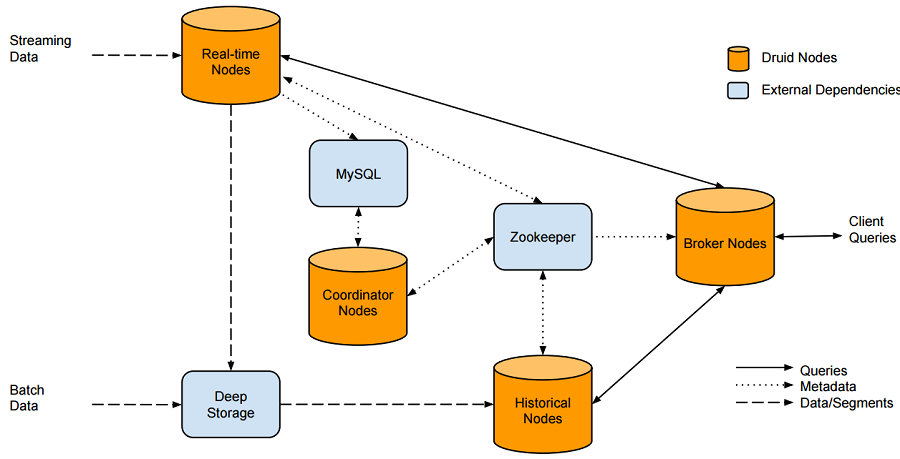
[ Architecture ]

참고 > http://www.popit.kr/time-series-olap-druid-%EC%9E%85%EB%AC%B8/
실시간 데이터의 경우 : real-time node > deep storage에 저장
배치 데이터 : deep stroage에 저장
mySql : druid 관련 메타정보 저장
coordinator : 메타정보를 통해 segment life cycle 관리
zookeeper : druid 내부 컴포넌트간 통신
broker : 사용자 query
[ Indexing Service ]

indexing : segment를 생성하거나 삭제하는 역할
Druid의 indexing service는 위의 도식과 같이 세가지 컴포넌트로 구성된다.
1. Peon : 단일 jvm에서 수행되는 하나의 태스크를 말하며 Middle Manager에 의해 생성된다.
2: Middle Manager : 요청된 작업 분배 등의 Peon을 관리하는 역할을 수행한다.
3: Overload는 task의 분산을 관리하며 local또는 remote의 다수의 Middle Manager를 구성할 수 있다.
indexing을 위해서는 Overlord node 를 통해 다음과 같은 URI에 수집 spec json을 포함하여 인덱싱 요청을 보낸다. 이때는 수집 대상 정보와 인덱싱을 위한 스키마 정보 등이 포함되며 수집 task가 생성된다.
http://<OVERLORD_IP>:<port>/druid/indexer/v1/task
= data를 load 한다는 뜻.
댓글 없음:
댓글 쓰기